 Docker has changed the development landscape for web and API application development. The increased speed, flexibility and security made possible by containers has led to dramatic increase of interest in using that same technology through the entire application lifecycle. Many technologies have evolved to make this possible. Amazon Web Services’ (AWS) Elastic Container Service (ECS), Redhat’s OpenShift, and Kubernetes are just some of the options to help speed the deployment of these new applications. Before venturing into this new containerized world, we will point out one important aspect. Containers are not virtual machines. Despite many container images have familiar names attached to them like Ubuntu, and Debian, there is a fundamental difference. While VMs focus on providing a virtualized full operating system and machine environment, containers are focused on application virtualization. Instead of covering the myriad of options and performance tweaks possible for each underlying container deployment platform, we will Instead focus on three application focused areas that can help ensure predictable performance.
Application Suitability Just because you can does not mean you should. The first thing to examine in deploying a containerized application is suitability. Microservice based applications and systems are designed to be ephemeral, scale horizontally, and consume smaller quantities of resources. These qualities make microservice based applications a natural fit to perform well in a containerized environment. Large monolithic applications are not typically the best suited for production deployment in containers. These legacy applications typically consume large amounts of resources, scale vertically, and can have dependencies on persistent storage. These qualities make it difficult for them to scale and perform well in a containerized environment. Application Communication and Consumption Getting from here to there (safely). A service mesh/map registers services available, and the containers that exist for that service. It also introduces an encrypted secure communications channel for the services to communicate over. Implementations such as Istio, Consul, and AWS App Mesh/Cloud Map among others allow for advanced traffic management within a container management system cluster. Incorporating a service mesh into your system can significantly help with ensuring performance, availability, discoverability, and security of your system by making sure it can scale efficiently and securely. Application Instrumentation Who is on first? The distributed nature of microservices based systems/architectures can make it difficult to determine what is causing a performance problem in the system. Utilizing distributed tracing within an application allows you to monitor application performance as a whole and find performance bottlenecks more easily across the multiple microservices that make it up. Distributed tracing systems such as Jaeger, AWS X-Ray, New Relic, and Data Dog among others, allow for inspection of the performance and timing of each micro service. This allows for your team to focus on the trouble areas. Without comprehensive distributed tracing, monitoring and logging, achieving predictable performance in a large, containerized ecosystem is challenging. Keeping these three areas in mind while planning your containerized future will help to ensure you are well positioned for predictable performance in the containerized world.
1 Comment
 Waterfall and Agile are two popular project management approaches; different and both beneficial enough to poise a dilemma for solution delivery. Agile’s key tenet is to provide flexibility while waterfall is based on a sequential approach to solution delivery. Choosing Agile or Waterfall, however, is becoming less of a choice as more organizations discover they require a mix of the two. to edit. 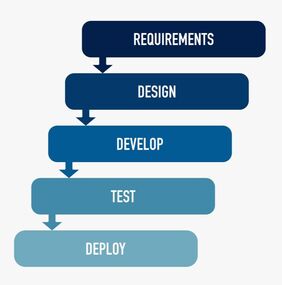 Waterfall Approach The traditional Waterfall model gives the solution team meticulous upfront planning, resulting in detailed project plans and comprehensive documentation of requirements that enables projects to:
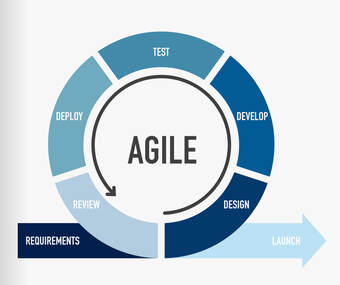 Agile Approach
Agile was created in direct response to waterfall’s rigid processes, comprehensive documentation and sluggish response to change and feedback. Agile’s frequent delivery allows the customer to provide constant feedback, flexible response to changes in requirements and continual improvement, resulting in a higher-quality product. A considerable disadvantage for Agile lies in the very reason for its creation; it doesn’t provide a clear roadmap to end-state delivery which can result in scope confusion, longer ramp-up time for new team members and idle time for the development team who often have to wait for requirements documentation to catch up with the sprint cycles. The Scaled Agile Framework (SAFe®) in particular allows for enterprise-level application of lean-agile practices by providing an implementation roadmap at the Program Increment (PI) level, forecasting deliverables a few months ahead while also allowing for longer-term solution planning that can span multiple years. Project success depends upon teams spending the time to tailor the solution delivery approach, mixing methodologies to formulate the best practices needed to meet the unique needs of the project. The solution when we play together: In the best of both worlds, we would have a methodology that enables:


At first glance, process improvement might seem like the sleepy topic you find in afternoon breakout sessions on the last day of a conference (back when we used to go to conferences, that is). Start talking about the time and money saved from optimizing processes and you may just get promoted to a morning workshop. The truth is, process improvement becomes the stuff of keynotes when you look closely at some use cases that rest at the very heart of survival and security for the enterprise. Appreciating the Impact of Process Consider how mergers and acquisitions demand reconciliation of entire legacy cultures and organizational systems. This is process improvement writ large, where decisions ripple across the whole post-merger enterprise and create outsized impacts – vast ROI when done skillfully, anemic productivity and poor risk management when not. Or imagine you’re enhancing controls around personally identifiable information (PII) in a Fortune 1000 company or similarly sized government agency. Transforming what might be thousands of such controls shouldn’t be a disparate hodgepodge of spreadsheets and other manual tools, since this increases the chance of error and regulatory risk. Your process improvement here would be to automate controls, thereby reducing compliance risk. These are mission-critical examples; yet the impact can be deceiving, since even the most life-saving adjustments for the organization might still present themselves as tedium. Securing the Enterprise...with Process The typical workflow for an employee exit might involve a dozen or more steps to disable network accounts, recover equipment, and remove RSA tokens, licenses, and other permissions. This drudgery might be assigned in a single ticket that can take a support staff member hours to get through. In a world of growing insider threats, that’s a problem. The remedy comes in a process improvement we’ve helped enact for some of our own clients. It involves breaking up the sclerotic workflow into smaller tickets and detailing SMEs in each area to work concurrently, or with automated cascading of ticketing. This modular approach ensures the most important protective actions, like disabling network access, can get done right away – thereby saving valuable time that might otherwise be used for data exfiltration or other damage to the organization. Every innovation like this requires the legwork of identifying baselines and current business rhythms, tying them to KPIs, and then further optimizing and customizing processes in strategic, cost-effective ways. It’s also helpful to federate agile principles across the workforce, so everyone is trained to think in new ways about process improvement in the first place. All of this is easier said than done, especially given the additional strictures of curating a new process within the preferences and realities of your client environment, especially highly-regulated and standardized government settings. But it’s well worth the peace of mind that comes with a more efficient and secure organization. 
Automation is increasingly a necessity in the enterprise, a juggernaut of use cases fueling lots of guidance – from ITIL’s succinct “Optimize and Automate” credo, to deeper dives by media and industry analysts on the fine art of when, where, and how to apply automation. At SES, we also get requests for something in the middle – a quick rule-of-thumb evaluation, just a step beyond a governing principle and meant to shape whether a deeper assessment to consider automation might be warranted. Gaining a High Level Assessment For the high level gut checks we’re talking about, consider these 3 key assessment guidelines that tend to play an outsized role in deciding when and where to automate:
Making it All a Reality in the Enterprise You’ll find these factors play a role in most automation decisions. For example, it could be the Frequency of Occurrences is driving your decisions on where to build automated job scheduling algorithms. Or perhaps you’re assessing the Maturity of your monitoring team’s handling of alert de-duplication before deciding whether to automate that particular process. And ROI and Business Value in a modernization project can help gauge whether a certain legacy process is worth automating before that process gets retired at some point in the future. The takeaway here is that automation has a cost, so your decisions should be guided by North Star principles around risks and opportunities, just like any other organizational investment. 
Modern enterprises are increasingly positioning the CISO, Chief Risk Manager, and other risk-focused leadership roles prominently within C-Suite decision making. It’s part of a trend toward elevating and centralizing the Risk Management function to address growing digital risks in the enterprise. Unfortunately, many firms still struggle to implement Risk Management throughout the actual organization. Among the biggest questions: Who, exactly, is responsible for collectively identifying and mitigating all the specific risks that pop up everywhere across the enterprise? Let’s take a closer look at how – while every organization needs to build its own programmatic response to that question – the underlying answer remains a fairly simple and holistic one: Risk Management should be a shared responsibility for everyone in the organization! A Collective View of Risk: Anyone Can be a “First Responder” The idea that everyone should be prepared to wear the Risk Manager hat during the course of a project doesn’t fit neatly into an org chart, but it’s a reality that SES and other companies at the forefront of Risk Management have come to accept: Vulnerabilities are so replete across most organizations today that everyone – regardless of role – is now a potential first responder against risk. This global view of Risk Management can be the foundation for proactive, reliable, and secure management of even the most sensitive and mission-critical projects. Consider, for instance, the SpaceX mission to the International Space Station in May of this year. The success of that mission served as a rare bright spot in a season of otherwise bleak news about Coronavirus. And, as SpaceX Mission Director Benjamin Reed explained in one of the pre-launch briefings, much of the success can be tied to a proactive and all-inclusive risk management culture. “Don’t take offense when people challenge your work; we encourage it,” he said in the briefing. “Anybody can raise a risk. We have systems in place that actually can allow anybody in the company to open up what we call risk tickets. And they have a direct line to senior leadership to say ‘Hey, I’m worried about this,’ up to the moment of launch.” As it happened, the launch was indeed delayed in the last few minutes of countdown because of an emerging risk flagged by someone on the meteorological team. The system worked, and the mission went ahead with a follow up launch and successful completion – so successful that it’s a featured use case in SES’s own internal Risk Management training curriculum. Making it a Reality with Personal and Organizational Responsibility To be clear, addressing and mitigating a known risk is a specialized task that not everybody is equipped to do; the shared responsibility we’re talking about here is to identify and report risks and issues. To enable such a universal response capability – organizations must build their own combination of the right processes, workflows, IT assets, and other programmatic elements. Thankfully, there’s no shortage of guidance from PMI and others on how to build such a Risk Management program. Yet whatever your particular organizational or project solution may be around risk, make sure that the role of identifying and reporting risks remains a collective responsibility. Also ensure that the responsibility is reinforced on both the individual level, where everyone knows to raise an issue or risk, and on the organizational level in terms of processes and procedures for the universal and actionable reporting of risk. Once identified, risks must be properly socialized across program managers, scrum level teams, partner networks, and other stakeholders. All these steps are easier said than done, but they create powerful ROI from a more holistic approach to risk management. It’s one that benefits from both centralized management and a collective accountability and commitment on risk across the entire workforce. |
�
Archives
May 2022
Categories |
 RSS Feed
RSS Feed
|
|

|

|

|
8229 Boone Boulevard - Suite 885 - Vienna, VA 22182
© Systems Engineering Solutions Corporation 2003 - 2022
© Systems Engineering Solutions Corporation 2003 - 2022